闲话 22.10.13
闲话
压位trie怎么实现?哪天写一个
好于是今天卡了一天的常数
然后lyin十分钟给切了
没什么要写的诶今天
哦对了今天中午换起床歌了
瑞苹 不如新宝岛
谁有什么很诡异的题来作社论题材啊
[最近突然在唱moon halo 但是我想推的是崩三 所以不放歌词了]
关于CF896E
接着炒冷饭
维护一个个元素序列,有次操作,分为如下两种。
- 给定,将中所有大于的元素减去
- 给定,询问中,有多少个元素恰好等于
最近有人被 P4117 五彩斑斓的世界 这题恶心到了,我觉得有必要普及一下这题恶心卡常的原因。
最开始 P4117 是一道小清新分块题,数据范围啥的和 CF896E 都是差不多的 1e5,就是没有作为比赛题,稍微卡了卡限制。
然后 WC2019 Day4,mcfx 上去讲了一些卡常技巧。其中
拿 P4117 举 了 一 个 例 子。
具体是什么例子? 如何碾过标算。
暴力 by mcfx
使用指令集的暴力程序(总用时:2889ms / 内存:1068KB)

std by lxl
lxl的标程(总用时: 4312ms / 内存: 81948KB)
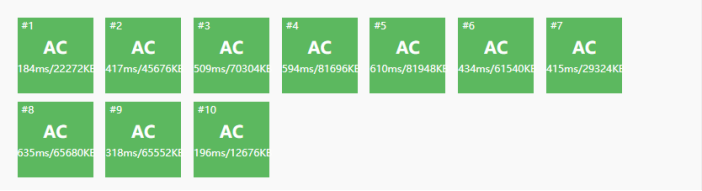
lxl寄了。然后lxl急了。
mcfx 在课件里打了这么一段话:
可惜的是,虽然除了常数,但是复杂度还是O(nm)。这导致如果n,m扩倍的话时间增长和标算差得远。比如n,m=3e5的时候指令集暴力就会原地爆炸,会比n,m=1e5慢整整9倍。。。
然后 P4117 的数据范围就变成了 1e6 和 5e5。
然后你该怎么写呢?“操作按块离线优化空间,大力卡常,数组压到最小,x+lazy 大于 的询问不处理,不在范围内的跳过。
最重要的是,所有的函数前面,加上inline。”
然后讲一下CF896E该怎么写。
这题的关键部分是两个东西:第二分块和均摊证明。
第二分块是什么?用于维护区间将所有 修改成 的操作。
我们首先进行一个分块,每块维护一个开在值域上的并查集,把所有值为 的节点都放在一个并查集里面。对于修改,整块直接把 的并查集连在 上,散块就暴力维护。并查集记录一下大小,修改的时候按大小维护对答案的贡献。
如果你不太会实现,可以先做一下板子。
给定长度为 的序列 ,你需要支持如下两种操作:
1.
1 l r x y,表示将 内所有值为 的元素的值改为 。2.
2 l r,表示输出 的值。。有 。任意时刻 不会超过 。
化完柿子照着上面的方式实现就行了。
code
#include <cstdio>
#include <cstring>
#include <cassert>
#include <algorithm>
using namespace std;
namespace Fread { const int SIZE = (1 << 18); char buf[SIZE], *p1 = buf, *p2 = buf; inline char getchar() {return (p1 == p2 && (p2 = (p1 = buf) + fread(buf, 1, SIZE, stdin), p1 == p2) ? EOF : *p1++);} }
namespace Fwrite { const int SIZE = (1 << 18); char buf[SIZE], *S = buf, *T = buf+SIZE; inline void flush(){ fwrite(buf, 1, S-buf, stdout), S = buf; } struct NTR{ ~NTR() { flush(); } }ztr;inline void putchar(char c){ *S++ = c; if(S == T) flush(); } }
#ifdef ONLINE_JUDGE
#define getchar Fread::getchar
#define putchar Fwrite::putchar
#endif
namespace Fastio{
struct Reader{ template <typename T> Reader & operator >> (T & x) {char c = getchar(); bool f = false;while (c < '0' or c > '9') { if (c == '-') f = true;c = getchar();} x = 0;while(c >= '0' and c <= '9'){x = (x<<1)+(x<<3)+(c^48);c = getchar();} if (f) x = -x;return *this;}Reader&operator>>(char&c){ c=getchar();while(c=='\n'||c==' '||c=='\r')c=getchar();return *this;}Reader&operator>>(char*str){ int len=0;char c=getchar(); while(c=='\n'||c==' '||c=='\r')c=getchar(); while(c!='\n'&&c!=' '&&c!='\r')str[len++]=c,c=getchar(); str[len]='\0'; return *this;}Reader(){}}cin;
struct Writer{ template <typename T> Writer & operator << (T x) {if(x == 0) return putchar('0'), *this;if(x < 0) putchar('-'), x = -x;static int sta[45], top = 0; while (x) sta[++top] = x %10, x /= 10; while (top) putchar(sta[top] + '0'), --top; return *this;} Writer&operator<<(char c){putchar(c);return*this;}Writer&operator<<(const char*str){int cur=0;while(str[cur])putchar(str[cur++]);return *this;}Writer(){}}cout;
} const char * endl = "\n"; const char * space = " ";
#define cin Fastio :: cin
#define cout Fastio :: cout
#define mod 998244353
#define RGE 10000005
#define N 100005
#define siz 390
#define rep(i,a,b) for ( register int (i) = (a); (i) <= (b); ++(i) )
#define pre(i,a,b) for ( register int (i) = (a); (i) >= (b); --(i) )
int n, q, a[N];
int fac[RGE], inv[RGE];
int bl[N], sz[N / siz + 5], st[N / siz + 5], ed[N / siz + 5], sum[N / siz + 5], prod[N / siz + 5], pw_fac[N][siz + 2], pw_inv[N][siz + 2];
inline int qp(int a, int b) {
int ret = 1;
while (b) {
if (b & 1) ret = 1ll * ret * a % mod;
a = 1ll * a * a % mod;
b >>= 1;
} return ret;
}
struct block_id {
int viv, cnt;
}g[N / siz + 5][N];
int fa[N], v[N];
inline int get(int x) {
return x == fa[x] ? x : fa[x] = get(fa[x]);
}
inline void init(int id) {
prod[id] = 1, sum[id] = 0;
rep(i, st[id], ed[id]) {
if (g[id][a[i]].viv) fa[i] = g[id][a[i]].viv, g[id][a[i]].cnt++;
else fa[i] = g[id][a[i]].viv = i, v[i] = a[i], g[id][a[i]].cnt = 1;
sum[id] += a[i];
prod[id] = 1ll * prod[id] * inv[a[i]] % mod;
}
}
inline void ps_d(int id) {
rep(i, st[id], ed[id]) {
a[i] = v[get(i)];
g[id][a[i]].viv = g[id][a[i]].cnt = 0;
} rep(i, st[id], ed[id]) fa[i] = 0;
}
inline void deal_side(int id, int l, int r, int from, int to) {
ps_d(id);
rep(i, l, r) if(a[i] == from) a[i] = to;
init(id);
}
inline void deal_whole(int id, int from, int to) {
sum[id] += (to - from) * g[id][from].cnt;
prod[id] = 1ll * prod[id] * pw_inv[to][g[id][from].cnt] % mod * pw_fac[from][g[id][from].cnt] % mod;
g[id][to].cnt += g[id][from].cnt;
if (g[id][to].viv == 0) g[id][to].viv = g[id][from].viv, v[g[id][to].viv] = to;
else fa[g[id][from].viv] = g[id][to].viv;
g[id][from].cnt = g[id][from].viv = 0;
}
inline void change(int l, int r, int from, int to) {
if (bl[l] == bl[r]) {
deal_side(bl[l], l, r, from, to);
} else {
int lf, rt;
if (st[bl[l]] != l) {
deal_side(bl[l], l, ed[bl[l]], from, to);
lf = bl[l] + 1;
} else {
lf = bl[l];
} if (ed[bl[r]] != r) {
deal_side(bl[r], st[bl[r]], r, from, to);
rt = bl[r] - 1;
} else {
rt = bl[r];
}
rep(i, lf, rt) deal_whole(i, from, to);
}
}
inline int qry(int l, int r) {
int tmpsum = 0, tmpprod = 1, tmp;
if (bl[l] == bl[r]) {
rep(i,l,r) tmp = v[get(i)], tmpsum += tmp, tmpprod = 1ll * tmpprod * inv[tmp] % mod;
} else {
int lf, rt;
if (st[bl[l]] != l) {
rep(i,l,ed[bl[l]]) tmp = v[get(i)], tmpsum += tmp, tmpprod = 1ll * tmpprod * inv[tmp] % mod;
lf = bl[l] + 1;
} else {
lf = bl[l];
} if (ed[bl[r]] != r) {
rep(i,st[bl[r]],r) tmp = v[get(i)], tmpsum += tmp, tmpprod = 1ll * tmpprod * inv[tmp] % mod;
rt = bl[r] - 1;
} else {
rt = bl[r];
} rep(i, lf, rt) tmpsum += sum[i], tmpprod = 1ll * tmpprod * prod[i] % mod;
} return 1ll * fac[tmpsum] * tmpprod % mod;
}
signed main() {
register int opr, l, r, x, y;
cin >> n >> q;
fac[1] = inv[1] = 1;
rep(i,2,RGE-5) fac[i] = 1ll * i * fac[i-1] % mod, inv[i] = 1ll * inv[mod % i] * (mod - mod / i) % mod;
rep(i,2,RGE-5) inv[i] = 1ll * inv[i] * inv[i-1] % mod;
rep(i,1,n) bl[i] = (i-1) / siz + 1;
rep(i,1,bl[n] - 1) sz[i] = siz;
sz[bl[n]] = ((n % siz == 0) ? siz : n % siz);
st[1] = 1;
rep(i,2,bl[n]) st[i] = st[i-1] + sz[i-1];
rep(i,1,bl[n]-1) ed[i] = st[i+1] - 1;
ed[bl[n]] = n;
rep(i, 1, N-5) {
pw_fac[i][0] = pw_inv[i][0] = 1;
rep(j, 1, siz + 1) {
pw_fac[i][j] = 1ll * pw_fac[i][j-1] * fac[i] % mod;
pw_inv[i][j] = 1ll * pw_inv[i][j-1] * inv[i] % mod;
}
}
rep(i,1,n) cin >> a[i];
rep(i,1,bl[n]) init(i);
rep(i,1,q) {
cin >> opr >> l >> r;
if (opr == 1) {
cin >> x >> y;
if (x == y) continue;
change(l, r, x, y);
} else {
cout << qry(l, r) << endl;
}
}
}
然后是第二个部分:均摊证明。
你发现原题的第一个操作有点不一样。然而,对于每块的修改都是 的,这样能导出 的整块部分时间复杂度。又因为散块在每次询问中都只会被修改 块,因此能得到总的时间复杂度 。
证明
考虑均摊证明方法。这里认为值域为 。
我们只需证明对于每个整块的修改都是 的。
考虑一次修改的意义。一次对某整块中大于 元素的修改使得该块内元素最大值和小于等于 。容易发现有意义的修改最多执行 次,值域内每个元素最多会被包含在一次修改中。
因此每块作为整块的复杂度都是 的。
杂题
题面长,不放。
假如说一条路径被走了两次,那这条路径是不会被算贡献的。因此最终的答案一定是一堆环和一条路径拼起来的。
我们首先找到所有的环。将环上路径的xor和扔进一个线性基里面。
然后我们随便找一条 的路径,查询线性基和这条路径xor和的最大值。
容易发现这样能够枚举所有情况,因为最大路径一定能由任意一个路径和最大路径组成的环xor那条路径得到。
code
#include <bits/stdc++.h>
#include <bits/extc++.h>
using namespace std;
#define rep(i,a,b) for (register int i = (a), i##_ = (b) + 1; i < i##_; ++i)
#define pre(i,a,b) for (register int i = (a), i##_ = (b) - 1; i > i##_; --i)
const int N = 1e6 + 10, mod = 1e9 + 7; typedef long long ll;
int n, m, t1, t2;
ll t3;
#define Aster(s) for (int i = head[s]; i; i = e[i].next)
#define v e[i].to
#define w e[i].wei
int head[N], mlc;
struct ep {
int to, next;
ll wei;
} e[N << 1];
void adde(int f, int t, ll wei) {
e[++mlc] = { t, head[f], wei };
head[f] = mlc;
e[++mlc] = { f, head[t], wei };
head[t] = mlc;
}
struct LB {
ll a[65];
void insert(ll k) {
pre(i,60,0) {
if (((k >> i) & 1) == 0) continue;
if (a[i] == 0) { a[i] = k; break; }
else k ^= a[i];
}
}
ll query(ll val) {
pre(i,60,0) if ((val ^ a[i]) > val) val ^= a[i];
return val;
}
} L;
ll tmp[N];
bool vis[N];
void dfs(int u, ll res) {
tmp[u] = res; vis[u] = 1;
Aster(u) {
if (!vis[v]) dfs(v, res ^ w);
else L.insert(res ^ tmp[v] ^ w);
}
}
signed main() {
ios::sync_with_stdio(false), cin.tie(0), cout.tie(0);
cin >> n >> m;
rep(i,1,m) cin >> t1 >> t2 >> t3, adde(t1, t2, t3);
dfs(1, 0);
cout << L.query(tmp[n]);
}
以下是博客签名,与正文无关。
请按如下方式引用此页:
本文作者 joke3579,原文链接:https://www.cnblogs.com/joke3579/p/chitchat221013.html。
遵循 CC BY-NC-SA 4.0 协议。
请读者尽量不要在评论区发布与博客内文完全无关的评论,视情况可能删除。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)